Está bastante interesante como funciona, usa likelihood probabilities, en Aprendizaje o Machine Learning, se usa mucho para diversos métodos de aprendizaje.
No conocía en lo personal yo el de Markov, y de hecho Viterbi se basa en este método para su funcionamiento ,Belive it or no, es bastante straight foward.
Je, veamos sí es tan cierto,intentaré explicarlo:
Viterbi: Es un algoritmo de decodificación, desarrollado a finales de 1960 por Andrew Viterbi. Los decodificadores Viterbi, han sido la manera más efectiva de decodificar comunciaciones de voz inalámbricas en transmisiones satelitales y de celular. Viterbi saca ya sea 0 o 1, dependiendo de lo que estima, que es el bit de entrada.El algoritmo de Viterbi, brinda una manera eficiente de encontrar la secuencia de caracetres con mayor probablidad a posteriori, (MAP)
Para ilustrar como funciona el algorimto de Viterbi, daré un pequeño ejemplo:
Assúmase, que se tiene un alfabeto de 4 letras, A={T,A,C,O}, y que se tiene un Optical Character Readers , un lector de caracteres, el cual intentará leer palabras que sean válidas del inglés. Supónase, que la cadena observada por la maquina OCR es: Z= -CAT-, donde el "-" denota espacios en blanco. Los vectores característicos z1, z2, and z3 son obtenidos cuando el extractor de característica detecta a C,A,T. (GATO en español, y es una palabra válida del idioma inglés.)
La información disponible obtained y relevante que el algoritmo Viterbi utliza para tomar una decisión, se expresa en término de la gráfica direccionada, que se muestra a continuación. Todos los nodos, excpetos los que están en blanco "-", poseen una probablidad ascosciada a ellos.
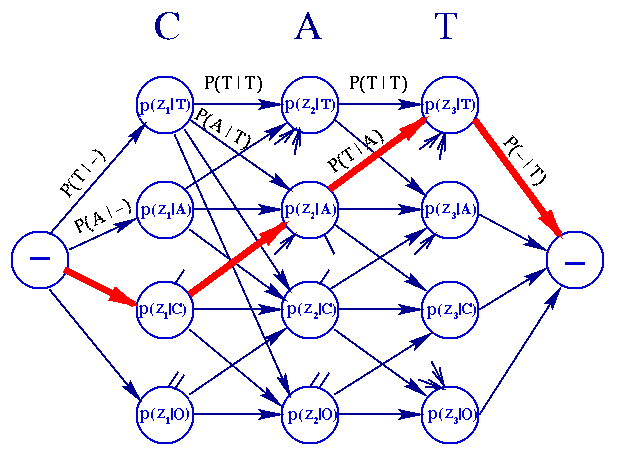
Vemos, de la figura , que cualquier camino , de un nodo principio, hasta un nodo final, represneta una secuencia de letras, mas no necesariamente una palabra válida. Se trata de hallar la sequencia de letras que maximizen el producto de probabilidades en su camino. Esto se puede lograr, al porcesar los nodos verticales, paso por paso de izqueirda a derecha. De este modo, si se agregan los logaritmos de las orillas, y las probabildiades de nodo, del camino, obtenemos:
gGAT(z1,Z2,Z3)=logp(z1|C)+logp(z2|A)+ logp(Z3|T)+log[P(C|-)P(A|C)P(T|A)P(-|T)]
Con este modelo, las letras del idioma inglés se visualizan como salidas, de un proceso de M estados de Markov, donde M es el número de caracteres distinguibles, si se trata de letras, el número será de 26, ya que el alfabeto del idioma inglés, pose 26 letras. En cada etapa de la secuencia (palabra), las 26 más probables secuencias se procesarán, la secuencia más probable que terminé en A, la secuencia más probable que termine en B, etc. En la etapa final, la secuencia más probable es seleccionada.
